Applicant
Dr. Klaus Dolag
Universitäts-Sternwarte München
Scheinerstr. 1 D-81679 München
Project Summary
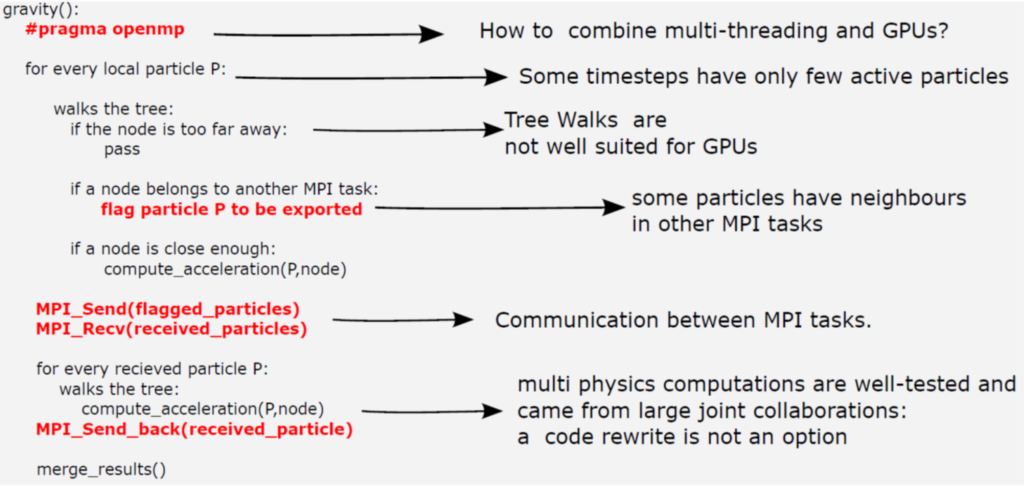
OpenGadget3 is a fully OpenMP/MPI parallelized version of the cosmological code P-Gadget3 which in its different versions is among the most often used codes for performing cosmological simulations within the astrophysics community worldwide. It allows to follow a large number of physical processes (like gravity, magneto-hydrodynamics, transport processes, sink particles and sub-grid models to follow chemical networks, stellar evolution, treatment of supermassive black holes and many more), all needed to successfully describe the formation of cosmological structures and the galaxies within. The currently largest simulation (Box0 from the Magneticum project) was following more than 1011 resolution elements, employing a full hybrid MPI/OpenMP implementation, using 172032 tasks on SuperMUC-II (LRZ). Enabling such complex, highly optimized code for GPU/Accelerators places a major challenge on the algorithmic and implementation side, as this can be only done in a hybrid way, where GPU/Accelerators are added as a further level of parallelization. Figure 1 shows a pseudo code for the gravity part of the code, highlighting this challenge of coupling a massive MPI/OpenMP hybrid algorithm to GPU/Accelerators.
Within this KONWHIR-III project, we further developed an offloading scheme based on OpenACC transforming OpenGadget3 in a full hybrid, MPI/OpenMP/OpenACC code where GPU/accelerator and CPU are overlapping their different tasks. This scheme has several advantages. First, and most importantly, the various modules which treat the different physical processes and contain the work of dozens of PhD students had to be only changed minimally. Secondly, and also very important, we could keep one version of these modules, independently if they are compiled for running on CPU or GPU/Accelerators allowing for a maximum flexibility and causing a minimum of maintenance. This was achieved by carefully splitting the work into a local primary loop which can be unconditionally performed on GPU/Accelerator and a secondary loop, which filters only the parts which need MPI communication which is in parallel performed on the CPU. Communication between CPU and GPU is done explicitly and based on reduced data structure to foster fast transfer of large blocks of data. This concept has been proven to work in the gravity, hydrodynamic and transport modules and we demonstrated that we could get a total speedup of factor 2-3 for a whole simulation, even in case of optimizations like adaptive time-stepping and small number of active particles on the smallest time-bin.