

Applicant
Yoshiyuki Sakai und Michael Manhart
Chair of Hydromechanics
Technical University of Munich
80333 Munich, Germany
Project Summary
We performed a SIMD-focused node-level optimisation on our in-house incompressible Navier-Stokes solver MGLET (Multi Grid Large Eddy Turbulence), which is capable of direct numerical simulations (DNS) as well as large-eddy simulations (LES) of turbulent flows in arbitrary-shaped domains (see Figure 1 for examples of MGLET application).

This optimisation work was motivated by the fact that the modern HPC processors are equipped with ever more powerful internal vectorisation hardware to realise both performance growth and reduction in energy consumption. Our main targets of the optimisation were MGLET’s two linear solvers for pressure Poisson problem: a red-black version of Gauss-Seidel solver with over-relaxation (SOR), as well as a Strongly Implicit Procedure (SIP) solver, which consume more than 50% of wall time in typical simulations. Both linear solvers are characterised by low arithmetic intensity, implying that meaningful SIMD optimisation must be accompanied by strategies for improved memory access. Moreover, the related communication routines implemented in MPI needed to be optimised as well, since those pressure solvers require frequent communications between sub-domains. The hardware target for this optimization was set to the SuperMUC-NG supercomputer hosted by Leibniz Supercomputing Centre (LRZ).
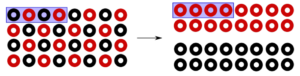
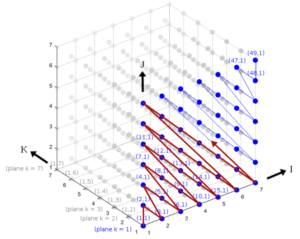
Our optimisation efforts included, but were not limited to: i) use of mixed-precision to relax the pressure on the cache hierarchy for the pressure solver routines (SOR, SIP); ii) in-place computation of the central SOR coefficients for further reduction of the cache pressure; iii) red-black memory rearrangement of the arrays accessed by the SOR solver (cf. Figure 2) to reduce cache misses while fostering vectorisation by making the memory access pattern unit-strided; iv) adaptation of the MPI-communication routines to the red-black data structure (SOR); v) memory rearrangement of the SIP arrays into a hyperline order (cf. Figure 3) to resolve the original algorithm’s inherent data dependency and transform the default irregularly-strided memory access pattern into uniformly-strided one, both contributing to enable vectorisation; vi) re-implementation of the MPI-communication routines utilising a manually packed and unpacked communication buffer, since the non-buffered alternative based on highly-irregular custom MPI datatype was found to be prohibitively slow. Depending on the simulation case, the runtime of MGLET could be reduced by 20 to 25% thanks to the SIMD optimisation performed over this project. Despite of the focus on SuperMUC-NG, the employed measures also prove similarly or even more effective on other modern CPU architectures (e.g. AMD Zen2). Accordingly, the code was successfully modernized and adapted to current macro-trends in hardware design. Referring to this achievement helped us in the application for further resources to realize large-scale projects. Most importantly of all, we learned that node-level performance is never fully separable from the MPI layer – an aspect that is hardly discussed in literature.
As for the previous two successful KONWIHR projects, the current project was supported by Dr. M. Ohlerich and Dr. M. Allalen of CFD-Lab@LRZ 1 . Over the course, we were assisted especially in performance profiling at the MPI as well as the node-level, compiler optimisation and optimised algorithm development. Without their generous support and patience, the current project could not be completed in the present form.